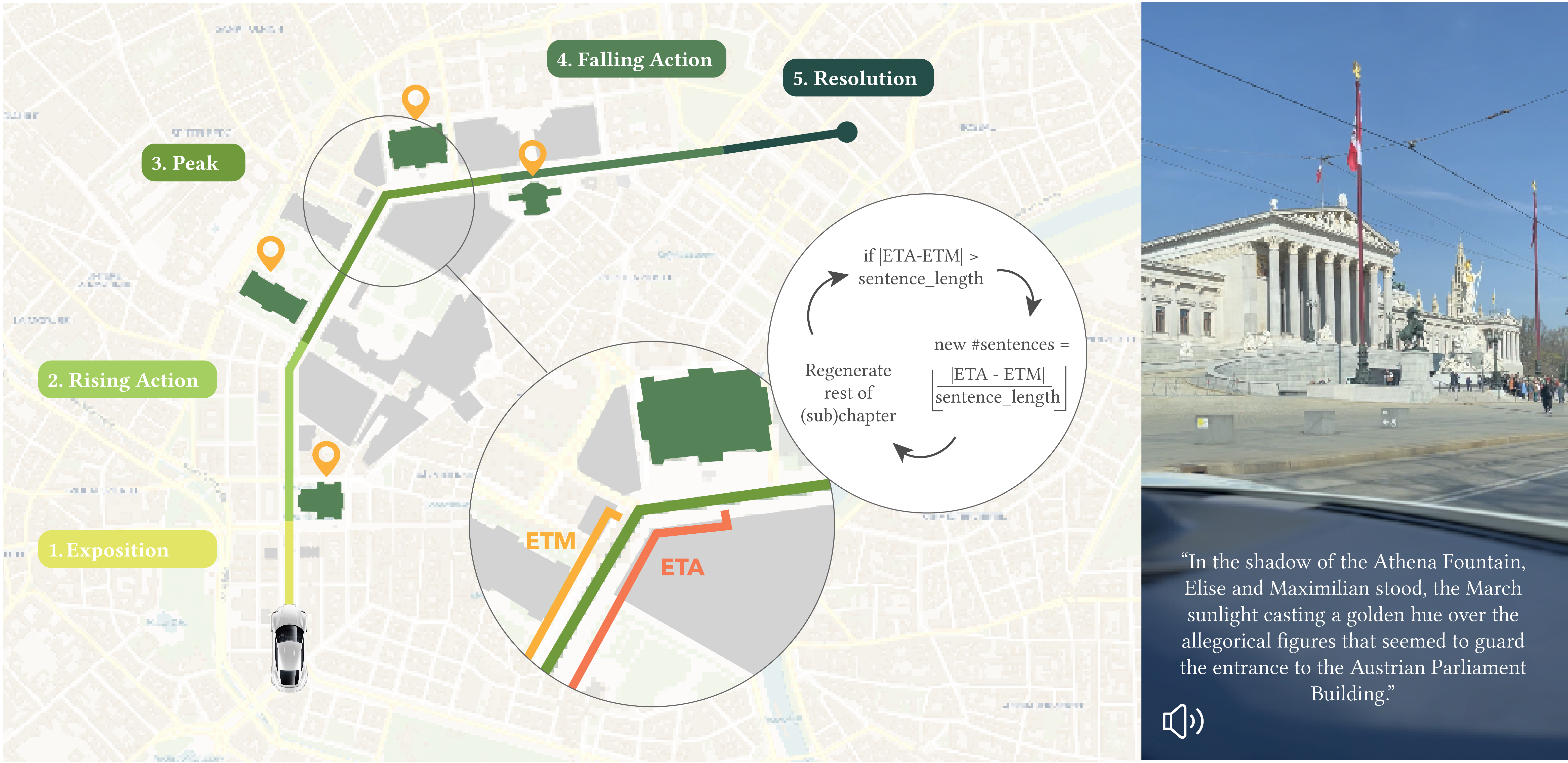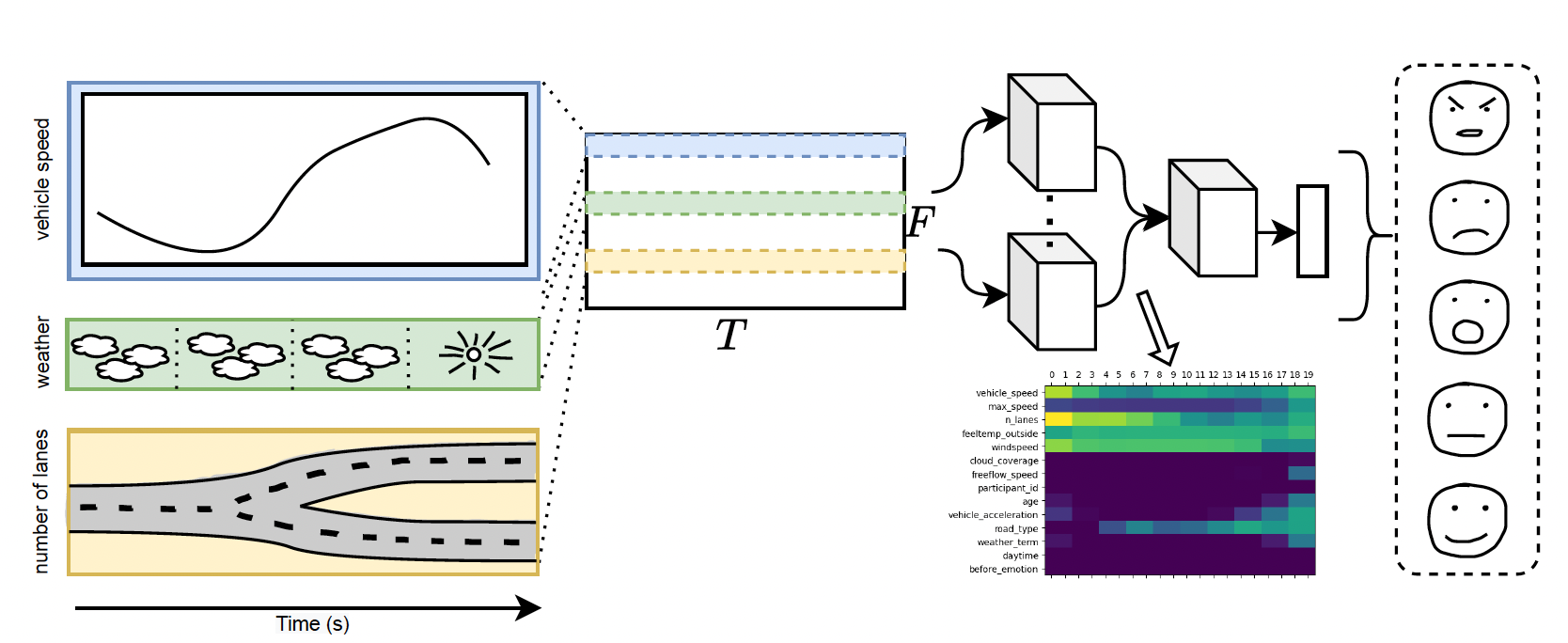
Modern automotive infotainment systems offer a complex and wide array of controls and features through various interaction methods. However, such complexity can distract the driver from the primary task of driving, increasing response time and posing safety risks to both car occupants and other road users. Additionally, an overwhelming user interface (UI) can significantly diminish usability and the overall user experience. A simplified UI enhances user experience, reduces driver distraction, and improves road safety. Adaptive UIs that recommend preferred infotainment items to the user represent an intelligent UI, potentially enhancing both user experience and traffic safety. Hence, this paper presents a deep learning foundation model to develop a context-aware recommender system for infotainment systems (CARSI). It can be adopted universally across different user interfaces and car brands, providing a versatile solution for modern infotainment systems. The model demonstrates promising results in identifying driving contexts and providing contextually appropriate UI item recommendations, even for previously unseen users. Furthermore, the model’s performance is evaluated with fine-tuning to assess its ability to make personalized recommendations to new users.

Philipp Hallgarten, PhD Candidate
Mail | LinkedIn | Scholar | Github
Hey! I am a Philipp, a 4th year PhD researcher at Porsche Human-Centered AI Research and Technical University of Munich. I am fascinated by leveraging context information with bleeding-edge AI systems to make interactions more adaptive and intelligent and thus create novel user experiences.
Human-Centered AI . Context-Understanding . Intelligent Interactions